Data Science is an interdisciplinary area, comprising several different topics. Considered as the sexiest area of the 21st century, Data Science consolidates the knowledge in Computer Science, Mathematics, Statistics, general areas, and business areas. That is why there are plenty of fascinating Data Science articles on the internet. If any blogger does not categorize their contents well enough, readers might find it difficult to get what they would like to know from the blog. Therefore, knowing how to categorise and tag properly will make your websites become more impressive and well-organized.
The differences between blog categories and tags
Categories are designed for broad grouping of posts. You can view them as general topics or the table of contents. Categories are hierarchical, meaning that we can add sub-categories.
Tags, on the other hand, are not hierarchical, meaning that you cannot create sub-tags on any sites. Tags are intended to describe the specific details of each post.
Tags can be any specific packages, languages, or tools described in a post, such as TensorFlow, Pandas, Python, R, ggplot2, etc. Also, they can be subjects of the contents like Deep Learning, Decision Trees, or Gradient Boosting.
Both tags and categories can be found on the right hand of your screen when editing a post on WordPress. A post can have no tags, but its category must be indicated. The default category is the “Uncategorised.”
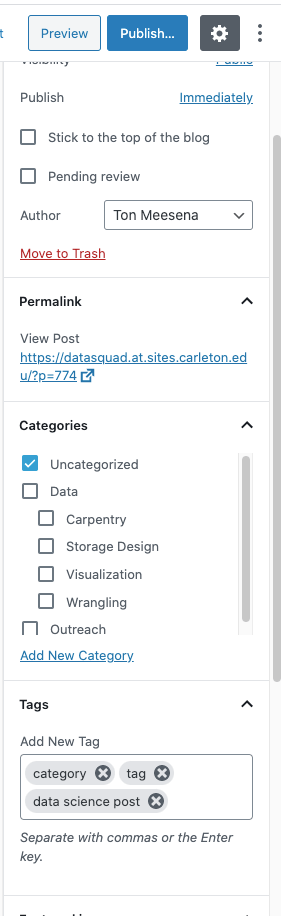
Categories on your Data Science posts
Different blogs can have different styles of categorisation. The categories are usually provided, and authors can select from the existing categories. Because categories are for broad grouping, there are conventionally not many categories in a website compared with the number of blog tags. Also, one post can be in several categories.
1. Data Manipulation
As you might observe, the posts on our DataSquad site are mostly about comparisons between different platforms, data management, and data manipulation. Instead of having Machine Learning or AI categories, our current categories are focusing on how we can manipulate raw data and achieve better performance.
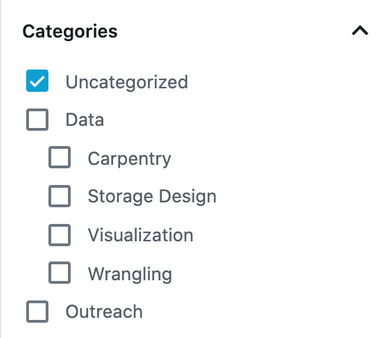
2. Areas in Data Science
This type of categories are more ubiquitous in popular websites where there are lots of people and experts come to share their knowledge. Their main categories usually are Big Data, Machine Learning, Artificial Intelligence, IOT, etc.

3. Sectors
Data Science can be used in several sectors, such as financial technology, healthcare sector, or different types of startups. So, these categories can also be seen in several sites.

Tags on your Data Science posts
Tagging your posts wisely can accommodate readers with a decent filter. Readers can use tags to filter all their needed content within a second. These following are some useful tags you might consider to tag before posting.
1. Languages and Packages
There are several programs and languages Data Scientists can use. It would be great if you can use every important language. However, some people might just prefer to work on only certain languages. Therefore, having tags on languages or packages can be helpful for readers who would like to filter all contents in their preferable languages. These tags can be Python, Java, R, Numpy, TensorFlow, Pandas, etc.
2. Levels of Difficulty
Different topics in Data Science blogs suit different groups of readers. Even though indicating the levels of difficulty can be subjective, it is still helpful for readers to evaluate the levels of any posts. The levels of difficulty, for example, can be beginners, intermediates, etc.
3. Areas
Data Science is an interdisciplinary area, and it can be used in several fields. Epidemiologists can use data to model the spread of Covid-19. The economists can utilize their data to evaluate the impacts of the pandemic and the appropriate economic remedies. Quantitative researchers can use several techniques to predict commodity prices and stock markets. Stating areas, such as Finance, Healthcare, Economics, etc, can help readers find areas they are interested in.
4. Usages
Data Science has lots of usages ranging from data visualisation, data cleaning, feature selection, feature engineering, classification, prediction to machine learning, and deep learning. Some readers might only want to know how they can plot and present their data effectively, and some people might be looking for how they can improve their machine learnings. Readers can get what they want easily by selecting their types of Data Science usage.
5. Techniques and Models
There are also several models in Data Science. Some people use just a simple technique like linear regression, and some people might use a random forest to predict their results. Also, these can be types of approaches, such as Time Series, Bayesian Statistics, or Stochastic Processes, etc. Indicating models and types of approaches will help readers quickly know what is going on in your posts.
References
- About the Editorial StaffEditorial Staff at WPBeginner is a team of WordPress experts led by Syed Balkhi. Trusted by over 1.3 million readers worldwide. (2020, June 09). Categories vs Tags – SEO Best Practices for Sorting your Content. Retrieved July 20, 2020, from https://www.wpbeginner.com/beginners-guide/categories-vs-tags-seo-best-practices-which-one-is-better/